The question is simple: is there any difference between the performance of the different service…
Hello, my name is Klaus Aschenbrenner, sitting in Vienna/Austria enjoying my life in Vienna/Austria, and providing with my company SQLpassion High Quality SQL Server Consulting Services across Europe. In this guest blog posting I want to give you an overview about Statistics in SQL Server, and what happens to the quality of your Execution Plans, when they are getting out-of-date.
As you might know Statistics are used by the Query Optimizer to estimate how many rows would be returned from a query. It’s just an estimation, nothing more. SQL Server uses within the Statistics object a so-called Histogram, which describes within a maximum of 200 Steps the data distribution for a given column.
One of the biggest limitations that we have with Statistics in SQL Server is the limitation of the 200 steps (which can be overcome with Filtered Statistics that were introduced back with SQL Server 2008). The other “limitation” is the Auto Update mechanism of Statistics: with a table larger than 500 rows, a Statistics object is only updated if 20% + 500 column values of the underlying table have changed. This means that your Statistics are getting updated more less as soon as your table grows.
Imagine you have a table with 100.000 records. In this case, SQL Server updates the Statistics object if you have done 20.500 (20% + 500) data changes in the underlying column. If you have a table with 1.000.000 rows, you need 1.000.500 (20% + 500) data changes. So the algorithm here is exponential and not linear. There is also the trace flag 2371 in SQL Server that influences this behavior. See the following link for more information about it.
So let’s switch over to SQL Server Management Studio to demonstrate this behavior and the side-effects that we are introducing with it. In the first step I’m just creating a new database, a simple table with 2 columns, and finally I’m inserting 1.500 rows into it:
CREATE DATABASE StatisticsDatabase;
GO
USE StatisticsDatabase;
GO
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
GO
-- Create a test table
CREATE TABLE Table1
(
Column1 INT IDENTITY,
Column2 INT
);
GO
-- Insert 1500 records into Table1
SELECT TOP 1500 IDENTITY(INT, 1, 1) AS n
INTO #Nums
FROM master.dbo.syscolumns sc1;
INSERT INTO Table1 (Column2)
SELECT n FROM #nums;
DROP TABLE #nums;
GO
When you make a simple SELECT statement against the table, you can see that we have in the 2nd column an even data distribution. Every value just occurs once in that column.
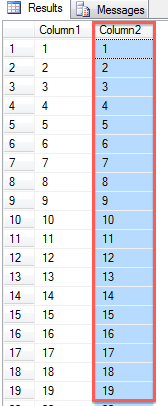
In the next step I’m creating a simple Non-Clustered Index on that column. With the creation of an index (Clustered, Non-Clustered), you are also getting an underlying Statistics object that describes the data distribution for your first key column in that index through the above mentioned histogram.
CREATE NONCLUSTERED INDEX idxTable1_Column2 ON Table1(Column2); GO
When you are now finally executing a SELECT * query against the table, and restricting on the 2nd column (where the Non-Clustered Index is defined), we are getting an Execution Plan with a Bookmark Lookup, because we have no Covering Non-Clustered Index defined:
SELECT * FROM Table1 WHERE Column2 = 2;
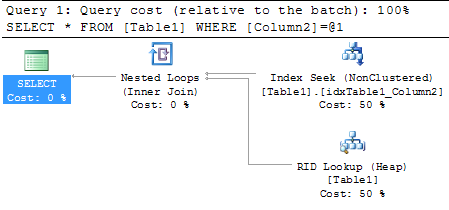
As you will also see from the Index Seek (Non Clustered) operator, SQL Server estimates 1 row (property Estimated Number of Rows), and in reality SQL Server processes 1 row (property Actual Number of Rows). This means we are dealing here with accurate Statistics, and the query itself just produces 3 Logical Reads.
In our case we are dealing now with a table of 1.500 rows, so SQL Server will automatically update the Statistics object of the underlying Non-Clustered Index when 20% + 500 rows have changed. When you do the math, you can see that we need 800 data changes (1.500 x 0,2 + 500).
What we are now doing in the next step is the following: we are working against SQL Server a little bit, and we are only inserting 799 new records into the table. But the value of the 2nd column is now always 2. This means we are now completely changing the data distribution of the table in that column. The Statistics objects thinks that 1 record is returned, but in reality we are getting back 800 rows (1 existing rows + 799 newly inserted rows):
SELECT TOP 799 IDENTITY(INT, 1, 1) AS n INTO #Nums FROM master.dbo.syscolumns sc1; INSERT INTO Table1 (Column2) SELECT 2 FROM #nums; DROP TABLE #nums; GO
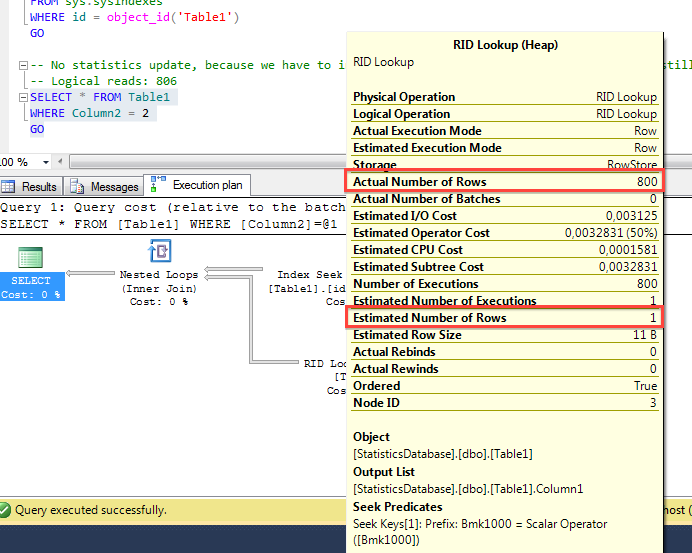
When you now run the identical SELECT statement again, SQL Server reuses the cached Execution Plan with the Bookmark Lookup. This means now that the Bookmark Lookup in the Execution Plan is executed 1.500 times, for every record once! This will also cost a lot of Logical Reads, SQL Server now reports 806 Logical Reads! As you can see from the following picture, the Estimated Number of Rows are now far away from the Actual Number of Rows. That’s one of the problems that you introduce with stale Statistics in SQL Server:
When we now insert one additional row into the table, we are hitting the current threshold when SQL Server will update our Statistics. In that case, the underlying Statistics object is marked as out-of-date, and the next query that will access the Statistics object (in our case, the following SELECT query) will trigger the synchronous update of the Statistics object. When these things have happened, SQL Server recompiles the Execution Plan, and will provide us afterwards an Execution Plan with a Table Scan operator, because our query is over the so-called Tipping Point (which only applies to Non-Covering Non-Clustered Indexes).
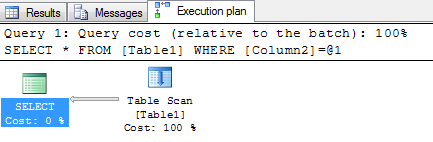
Our Logical Reads are now also down to 5, which means we are now executing a much better and faster Execution Plans as previously with the Bookmark Lookup.
I hope that you have now a much better understanding of Statistics in SQL Server, and which side-effects they will introduce to your Execution Plans, when they are out-of-date.
If you want to learn more about how to tune and troubleshoot your SQL Server installations, I can recommend you my SQL Server Performance Tuning & Troubleshooting Workshop, that I’m next March in Stockholm/Sweden.
Thanks for reading!
-Klaus