In some cases it can take extreme long time to transfer data with the OLE…
Hur påverkar tabell designen prestandan när man laddar större datamängder?
Anta att man vill ladda några mätvärden varje timme från 1 miljon enheter, dvs. 24miljoner rader ska laddas varje dag. Man vill sen söka/uppdatera dessa rader vilket gör att det måste finnas index som underlättar dessa operationer.
I grunden finns då 3 huvud varianter av tabell design:
- Heap (Med Identity kolumn och ett nonclustered index på enhet & tid)
Alla nya rader kommer att läggas sist i tabellen och det är bara det icke klustrat indexet som kommer att få fragmentering - Klustrad 1 (Clustered index på Identity kolumn och ett nonclustered index på enhet & tid)
Alla ny rader kommer att läggas sist i tabellen och det är bara det icke klustrat indexet som kommer att få fragmentering - Klustrad 2 (Clustered index på Enhet & tid)
Vi slipper det Icke klustrat indexet men får istället fragmentering av tabellen
För att titta lite närmare på hur det tabellerna beter sig har följande test gjorts på alla 3 tabell typerna:
– Tabellen skapad (se create scripten i slutet)
– 1 Tabell med 24 miljoner rader finns
– I en loop (60 dgr) laddades dessa 24 miljoner raderna in i test tabellen med en insert select.
– Ingen rebuild/reorganize gjordes av tabellen
Ladd tiderna visas i nedanstående diagram:
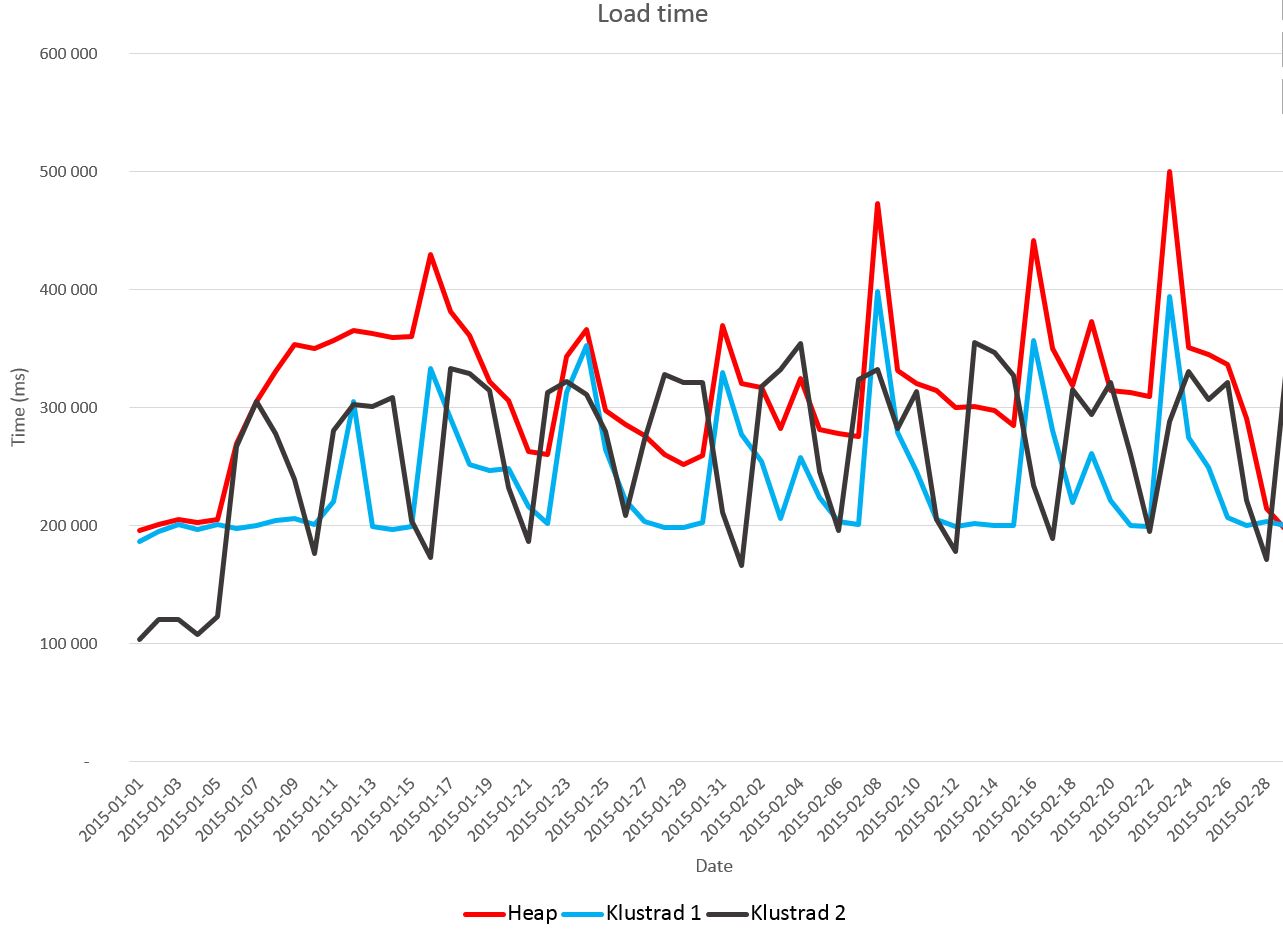
Man ser att snitt tiden för att ladda 1 dags data (24Miljoner rader) blev:
| Tabell typ | Snitttid (ms) |
| Heap | 320 000 |
| Klustrat 1 | 239 000 |
| Klustrat 2 | 270 000 |
Själva tiden är rätt ointressant utan det är mer intressant att se förhållande mellan dessa. Testen är genomförd på samma HW, med samma ladd script, samma grunddata, samma filstorlekar initialt i varje körning enda som skiljer är tabell designen.
Varför varierar tiden så mycket de olika dagarna? När man tittar på antalet nya pages som skapas under en dags laddning så får man förklaringen.
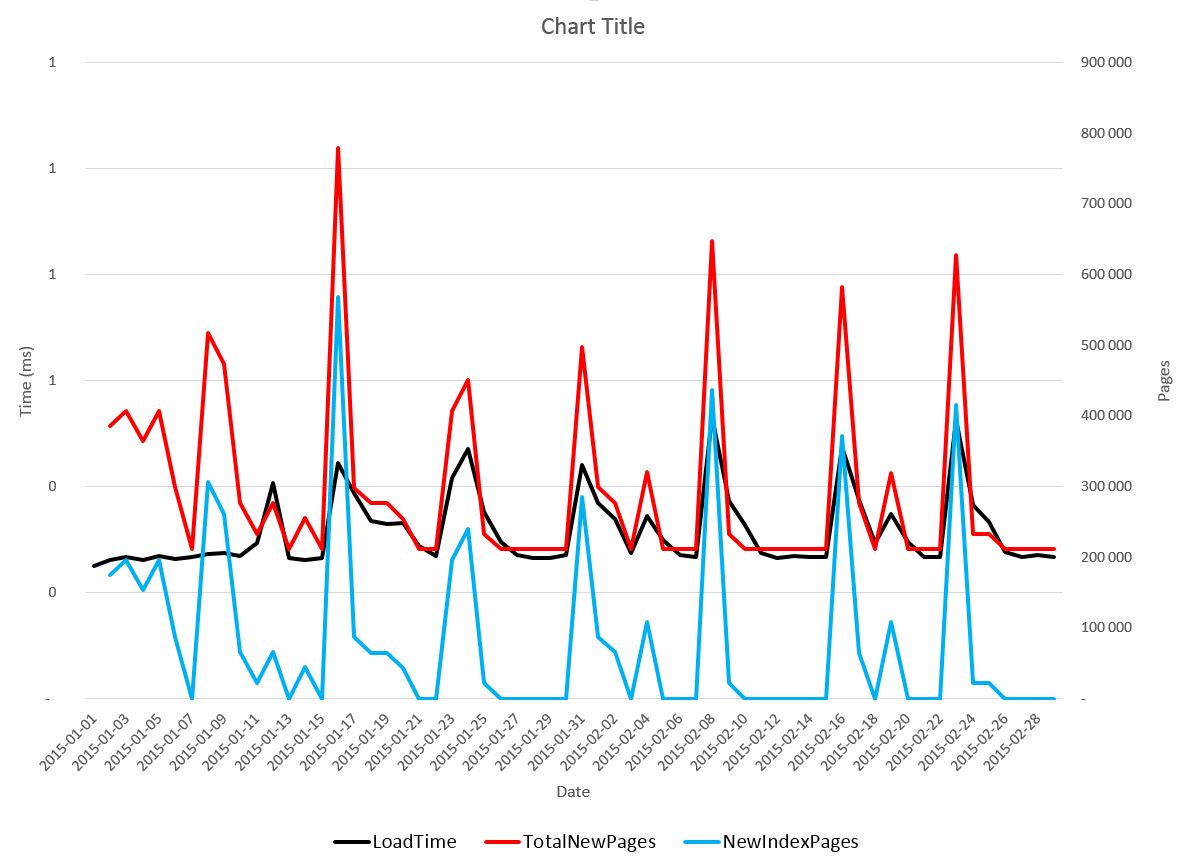
För att lagra den information (i detta fall Klustrat 1 tabellen) så behövs det skapas ca 211 222 pages (variation mellan 211 216 – 211 225) i själva tabellen. Alla dessa nya sidor kommer att hamna sist i tabellen och all ny rader kommer att läggas där i den ordningen de kommer in, detta styrs av att vi har en identity som vi klustrar på. Sidorna kommer dessutom att vara väl fyllda (99 %).
Däremot så ska ju raderna även in i det icke klustrade index (UnitId & Ts) på sin rätta på sin rätta plats. Då laddningen i detta fall är lika från dag till dag kommer ju ett visst UnitId att få fler och fler rader som ska ligga efter varandra med nya tider (Ts). När man inte får plats med fler rader på en sida måste man dela sidan för att kunna fortsätta att fylla på i UnitId & Ts ordningen. Då samma förfarande kommer att göras för alla UnitId så blir det en viss regelbundenhet i ökningen och därmed regelbundet längre ladd tider. Här är dock inte fyllnadsgraden av sidorna lika hög utan ligger på ca 80 %.
I nästa Blogg tittar vi lite på hur rebuild av det icke klustrade index påverkar laddningen.
Tabell utseende
-- Heap + NonCL index (UnitId + Ts) Create Table Test (Id BigInt Identity(1,1) NOT NULL, UnitId Int NOT NULL, Ts SmallDateTime NOT NULL, V1 Decimal(15,3) NULL, V2 Decimal(15,3) NULL, V3 Decimal(15,3) NULL, V4 Decimal(15,3) NULL, Status Int NOT NULL, Comment varchar(200) NULL, ExpFlag Int NOT NULL GO Create NonClustered Index IX_Test_UnitIdTs on Test (UnitId, Ts) on [Primary] GO -- CL index (Id) + NonCL index (UnitId + Ts) Create Table Test (Id BigInt Identity(1,1) NOT NULL, UnitId Int NOT NULL, Ts SmallDateTime NOT NULL, V1 Decimal(15,3) NULL, V2 Decimal(15,3) NULL, V3 Decimal(15,3) NULL, V4 Decimal(15,3) NULL, Status Int NOT NULL, Comment varchar(200) NULL, ExpFlag Int NOT NULL, Constraint PK_Test_Id Primary Key Clustered (Id)) On [Primary] GO Create NonClustered Index IX_Test_UnitIdTs on Test (UnitId, Ts) on [Primary] GO -- CL index (UnitId + Ts) Create Table Test (UnitId Int NOT NULL, Ts SmallDateTime NOT NULL, V1 Decimal(15,3) NULL, V2 Decimal(15,3) NULL, V3 Decimal(15,3) NULL, V4 Decimal(15,3) NULL, Status Int NOT NULL, Comment varchar(200) NULL, ExpFlag Int NOT NULL, Constraint PK_Test_Temp_Id Primary Key Clustered (UnitId, Ts)) On [Primary] GO