Have you ever removed a SQL Server database, and checked the box to remove the backup…
There are many different methods to kill SQL server performance and one of the most bullet proof methods is correleated subqueries. In this blog post I’ll try to explain what correlated subqueries are, why they kill the performance and how to avoid them.
First of all, what is a correlated subquery?
Well, it’s an inner query that is filtered by values from the outer query. Crystal Clear? Not really, lets give an example instead. First of all, I create two tables ….
CREATE TABLE table1 ( col1 INT IDENTITY(1,1) NOT NULL, col2 DATE NOT NULL ); GO CREATE TABLE table2 ( col1 INT IDENTITY(100000,1) NOT NULL, col2 DATE NOT NULL ) ; GO
…and then I write a correlated subquery…
SELECT
T1.COL2 ,
col1 = (
SELECT t2.[col1]
FROM [table2] AS t2
WHERE t2.[col2] = t1.[col2]
) --The inner query that is correlated with the outer query
INTO #TABLE3
FROM [table1] AS T1
Does this make sense? Well, as you can see, for every record in table1 I’ll want to get a record from table2 that is matching on col2. As a matter of fact, this query will fail if table2 will return more than one record for any of the records in table1. Do you see any problem with this approach? Well, in this case, if you execute the code, you will not have any performance issues as the tables are empty, but what will happen if you add a large number of records? You’ll kill the SQL server performance!
Why do correlated subqueries kill the performance?
Well, for every record you add in table1, SQL server has to execute the inner query in a nested loop. Lets add some data! In this case I add 1 000 000 records in table1 and table2, just for fun and to show the consequences.
;WITH cteNums AS ( -- I use this common table expression to create a list of numbers from 1 to 1 000 000 SELECT top 1000000 ROW_NUMBER() OVER(ORDER BY o1.object_ID) AS n FROM master.sys.columns o1 CROSS JOIN master.sys.columns o2 CROSS JOIN master.sys.columns o3 ) INSERT INTO table1 (col2) --insert into table1 OUTPUT INSERTED.col2 INTO table2 (col2) --use the output clause to insert into table2 SELECT DATEADD(d,n,GETDATE()) -- create dates from the list of numbers FROM cteNums;
Now I have two tables with 1 000 000 records in each, they contain the same set of data and it’s time to compare a correlate subquery with a simple join.
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; --first use a correlated subquery to populate a temp table to avoid the data transfer to the client SELECT T1.COL2 , ( SELECT t2.[col1] FROM [table2] AS t2 WHERE t2.[col2] = t1.[col2] ) AS col1 INTO #TABLE3 FROM [table1] AS T1 DBCC DROPCLEANBUFFERS; --second use a simple join to populate a temp table to avoid the data transfer to the client SELECT T1.COL2 , T3.col1 INTO #TABLE4 FROM [table1] AS T1 INNER JOIN ( SELECT t2.[col1] , T2.COL2 FROM [table2] AS t2 ) AS t3 ON T3.[col2] = t1.[col2] SET STATISTICS TIME OFF; SET STATISTICS IO OFF; DROP TABLE [#table3] DROP TABLE [#table4]
If you click the button “include actual execution plan” before you execute the code, you would get something like this:

As you can see, two completely different execution plans and according to Management Studio the cost of the first query is about 90% of the complete batch! Well, this is the estimate cost and may or may not reflect the reallity, but don’t forget that SQL server is using cost based optimizations to get “the best” execution plan. Anyway, estimated cost or not, it’s no rocket sience to understand that the second query is faster. To understand the difference, you can take a look at the join operators, nested loops vs hash match. When you have a nested loop you are going to execute the bottom branch for every record in the top branch. With the hash match join you get a result from both branches and match them together. If you need evidence for that statement you can hover with the mouse pointer over the index spool operator and “voilá”!
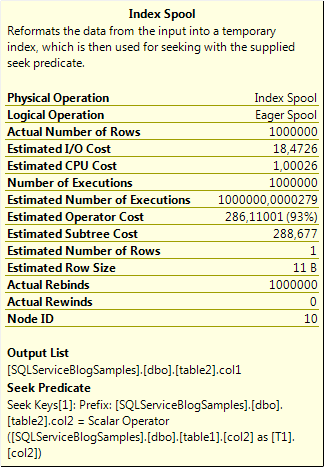
As you can see in this popup is that this operation is executed 1 000 000 times, and this is only a “reformatting” of data into a temporary index. The actual join operation is performed in the nested loop. In the second execution plan you can see that you have to table scans with a hash match and the table scans are only performed once. What impact did the execution plans have on elapsed time and number of reads? Well lets take a look at that! I guess you will not be surprised by now.
-- I add some options for the index to increase the read performance, you should avoid these settings in a "normal" table, --but in temp tables you can actually gain some performance as the indexes will be compact and --SQL server doesn't need to care about row or page locks CREATE CLUSTERED INDEX IX1 ON [table1] (COL2) WITH(FILLFACTOR=100, PAD_INDEX=ON, ALLOW_ROW_LOCKS=OFF, ALLOW_PAGE_LOCKS=OFF) CREATE CLUSTERED INDEX IX1 ON [table2] (COL2) WITH(FILLFACTOR=100, PAD_INDEX=ON, ALLOW_ROW_LOCKS=OFF, ALLOW_PAGE_LOCKS=OFF) SET STATISTICS TIME ON; SET STATISTICS IO ON; DBCC DROPCLEANBUFFERS; SELECT T1.COL2 , ( SELECT t2.[col1] FROM [table2] AS t2 WHERE t2.[col2] = t1.[col2] ) AS col1 INTO #TABLE3 FROM [table1] AS T1 DBCC DROPCLEANBUFFERS; SELECT T1.COL2 , T3.col1 INTO #TABLE4 FROM [table1] AS T1 INNER JOIN ( SELECT t2.[col1] , T2.COL2 FROM [table2] AS t2 ) AS t3 ON T3.[col2] = t1.[col2]; SET STATISTICS TIME OFF; SET STATISTICS IO OFF; DROP TABLE [#table3] DROP TABLE [#table4]
As you can see, the queries executes much faster with the clustered indexes, but the number of executions and the logical reads are still high and might affect the performance. Another thing to be aware of is that the correlated subquery migth return NULL if there are no match in the inner query and if that is the intended behaviour you need to change the INNER JOIN to a LEFT JOIN to get the same behaviour.